If you have a big task to do that needs a lot of computation, but can be split up in several independent smaller tasks, you can reduce the overall execution time by spreading the work to several CPUs or cores.
On a Linux/Unix system this can be done using fork(). On Windows, fork() is emulated by perl and it might not fully work the same way.
Skeleton fork-ing
First let's see how forking works.
When you call the fork() function of perl, it creates a copy of the current process
and from that point on, there are going to be two processes executing the same script in parallel.
In both "instance" of the script there will be all the variables that already existed in the original
process, but there is no connection between the variables of the two processes. There is no direct
way for one process to update (or even to check) the variables in the other process.
When we call fork() it can return 3 different values: undef, 0, or some other number.
It will return undef if the fork did not succeed. For example because we reach the maximum number of processes
in the operating system. In that case we don't have much to do. We might report it and we might
wait a bit, but that's about what we can do.
If the fork() succeeds, from that point there are two processes doing the same thing.
The difference is that in original process, that we also call parent process,
the fork() call will return the process ID of the newly created process. In the
newly created (or cloned) process, that we also call child process, fork()
will return 0.
The variable $$ contains the Process ID of the current process.
Let's see the following script:
use strict;
use warnings;
use 5.010;
say "PID $$";
my $pid = fork();
die if not defined $pid;
say "PID $$ ($pid)";
If we runt this script we will get output like this:
PID 63778
PID 63778 (63779)
PID 63779 (0)
Before calling fork, we got a PID (63778), after forking we got two lines,
both printed by the last line in the code.
The first printed line came from the same process as the first print (it has the same PID),
the second printed line came from the child process (with PID 63779). The first one received
a $pid from fork containing the number of the child process. The second, the
child process got the number 0.
Fork and wait
There are a couple of issue we need to improve.
First of all, usually we want the parent process and the child process to do different things.
We also usually want the parent process to wait till all of its child processes have finished
working, and exit only after that. Otherwise they child processes will become so-called zombies.
Let's see the next example:
use strict;
use warnings;
use 5.010;
my $name = 'Foo';
say "PID $$";
my $pid = fork();
die if not defined $pid;
if (not $pid) {
say "In child ($name) - PID $$ ($pid)";
$name = 'Qux';
# sleep 2;
say "In child ($name) - PID $$ ($pid)";
exit;
}
say "In parent ($name) - PID $$ ($pid)";
$name = 'Bar';
# sleep 2;
say "In parent ($name) - PID $$ ($pid)";
my $finished = wait();
say "In parent ($name) - PID $$ finished $finished";
In the child process $pid will be 0, and so not $pid will be true. The child process will execute
the block of the if-statement and will exit at the end.
In the parent process $pid will contain the process id of the child which is a non-negative number and thus
not $pid will be false. The parent process will skip the block of the if-statement and will execute the
code after it.
At one point the parent process will call wait(), that will only return after the child process exits.
There is also a variable called $name that had a value assigned before forking. If you look at the output
below, you will see that the variable $name kept its value in both the parent and the child process after
the fork, but we could change it in both processes independently.
PID 64071
In parent (Foo) - PID 64071 (64072)
In parent (Bar) - PID 64071 (64072)
In child (Foo) - PID 64072 (0)
In child (Qux) - PID 64072 (0)
In parent (Bar) - PID 64071 finished 64072
The above code also has two calls to sleep commented out. They are there so you can enable each one of them
separately to observe two things:
If the sleep is enabled in the child process (inside the if block) then the parent will arrive to the wait
call much sooner than the child finishes. You will see it really waits there and the last print line from
the parent will only appear after the child process finished.
On the other hand, if you enable the sleep in the parent process only, then the child will exit
long before the parent reaches the call to wait. So when the parent finally calls wait,
it will return immediately and return the process id of the child that has finished earlier.
This is important, as this means the signal that the parent process received marking the end of the child process has also waited for the parent to "collect" it. This will be especially important in the next example, where we create several child processes and we want to make sure we wait for all of them.
use strict;
use warnings;
use 5.010;
say "Process ID: $$";
my $n = 3;
my $forks = 0;
for (1 .. $n) {
my $pid = fork;
if (not defined $pid) {
warn 'Could not fork';
next;
}
if ($pid) {
$forks++;
say "In the parent process PID ($$), Child pid: $pid Num of fork child processes: $forks";
} else {
say "In the child process PID ($$)";
sleep 2;
say "Child ($$) exiting";
exit;
}
}
for (1 .. $forks) {
my $pid = wait();
say "Parent saw $pid exiting";
}
say "Parent ($$) ending";
In the $fork variable we count how many times we managed to fork successfully.
Normally it is the same number as we wanted to fork, but in case one of the forks
is not successful we don't want to wait for too many child processes.
As the child processes exit, each one of them sends a signal to the parent. These
signals wait in a queue (handled by the operating system) and the
call to wait() will return then next item from that queue. IF the queue
is empty it will wait for a new signal to arrive. So in the last part of the
code we call wait exactly the same time as the number of successful forks.
In the for loop, we called fork $n times.
In the part of the parent process (in the if-block), we just counted the forks.
In the child process (in the else-block) we are supposed to do the real work.
Here replaced by a call to sleep.
I am sure you are also familiar with people who go to work and then sleep there...
Anyway, the output will look like this:
Process ID: 66428
In the parent process PID (66428), Child pid: 66429 Num of fork child processes: 1
In the parent process PID (66428), Child pid: 66430 Num of fork child processes: 2
In the child process PID (66429)
In the parent process PID (66428), Child pid: 66431 Num of fork child processes: 3
In the child process PID (66430)
In the child process PID (66431)
Child (66431) exiting
Child (66429) exiting
Child (66430) exiting
Parent saw 66430 exiting
Parent saw 66431 exiting
Parent saw 66429 exiting
Parent (66428) ending
wait and waitpid
The wait function will wait for any child process to exit and will return the
process id of the one it saw. On the other hand there is a waitpid call that we don't
use in our examples, but that will wait for the end of a specific child process based on its
process ID (PID).
Spreading load to several cores
Lastly, let's see an example how we can spread load to several cores in your CPU.
For this probably the best tool to use is the htop command in Linux.
Please make sure you install it (yum install htop on Redhat/Fedora/CentOS,
or apt-get install htop on Debian/Ubuntu).
Then open a separate terminal and launch htop. At the top it should show several numbered
rows. One for each core in your computer. The vertical sticks show the load.
The following script is just testing if we can create load on several cores on the same machine. Tested on a MacBook htop showed 100% on all 4 cores.
The script will fork $n = 8 times. Each child process will
run a loop 10,000,000 times generating and adding together two random
numbers. Of course, we could have find some useful thing to do instead
of just generating random numbers, but this is a simple way to create
load on the CPU.
use strict;
use warnings;
my $n = 8;
for (1 .. $n) {
my $pid = fork;
if (not $pid) {
my $i = 0;
while ($i < 10_000_000) {
my $x = rand;
my $y = rand;
my $z = $x+$y;
$i++;
}
exit;
}
}
for (1 .. $n) {
wait();
}
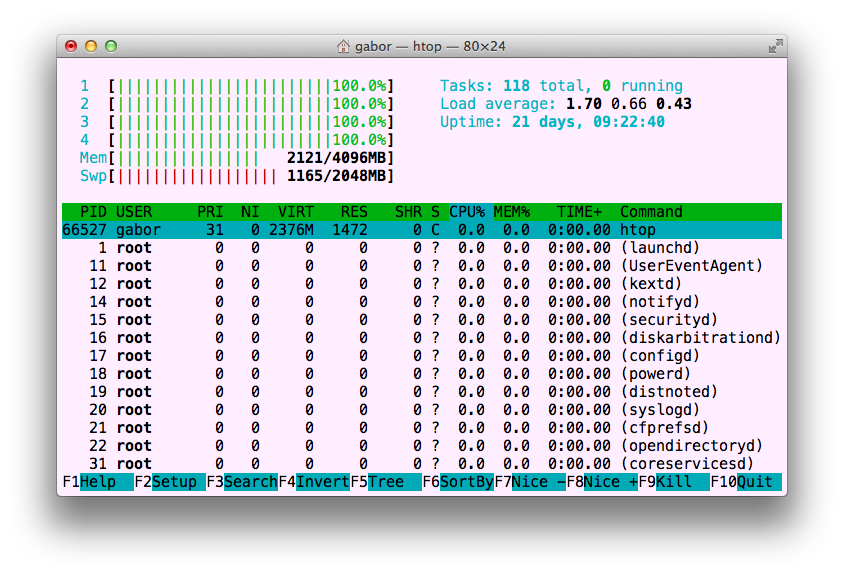
Run the script again and look at the output of htop:
All 4 cores are now filled with vertical sticks meaning all 4 cores have 100% CPU usage.
Communication
The big issue with forking is that once we forked, the two processes have no common variables. If the child process does something useful (as opposed to the above example) and wants to tell the parent process about the results it cannot do it directly.
There are several solutions to this, for example they can communicate via a socket. This will enable two way and long term communication, but it can be a bit complex. If we only want the child process to send the results back to the parent we can let the child save the results in a file and the parent can read the file after the child terminates.
We will see it in another article: Speed up calculation by running in parallel
Comments
simple and clear
Just signed up to support you on Patreon.
Your Perl Maven is most excellent. Thank You.
thank you!
How do you make unit test to test code contain "fork"
I just wrote this example: https://perlmaven.com/test-code-which-is-forking
Show me your case if this approach does not work there.
Hello Gabor! Quick question to check if there's a typo in one of the examples, or if I've missed something (more likely the latter).
On line 11 of the second example in the "Fork and Wait" section, there is this line of code:
"my $pid = fork;"
should the fork call have parens, i.e.:
"my $pid = fork();"
?
I'm tempting fate by posting this question before I read the rest of the explanation, so it's likely that the example was written correctly and the part I haven't read yet explains why... but then again if it doesn't and that's a typo, I'll look really S-M-R-T :)
In general in Perl you don't need to put parentheses for a function to be called. so fork and fork() are the same.
Whaaa...? Wow, I knew perl was lenient but I didn't know this. Thanks for teaching me something else new.
Just want to say thank you for this content. Perl is the only language common to all our Unix environments and learning it has been a real game changer for my efficiency.
