I used to work on an application where we wanted to let non-developers, and even managers to be able to provide input to our system in batches. We did not want them to fill a web form, as those usually have rather limited editing capabilities.
They were already familiar with Microsoft Excel, so letting them use that and send us the Excel files looked like a good way to get them involved.
Then we faced the issue, of given a file created by Microsoft Excel, how can we read the content while running on a Linux machine running Red Hat, or on a Solaris box.
CPAN has quite a few modules for reading Excel files. There is Spreadsheet::Read that provides a very high level abstraction but which means we might have no access to all the details hidden in the Excel file. On the other hand it will be able to handle other type of spreadsheets as well. In addition to Microsoft Excel files, it can also read OpenOffice, LibreOffice, SquirrelCalc, and plain CSV files. All of these with one simple interface.
Then there are the low-level libraries reading files by different versions of Excel: Spreadsheet::ParseExcel can read Excel 95-2003 files, and Spreadsheet::ParseXLSX can read file in the Excel 2007 Open XML XLSX format. There is also Spreadsheet::XLSX, but as far as I can tell that's not recommended any more.
In addition there is also Spreadsheet::ParseExcel::Simple that works at an abstraction level somewhere between the above two, but it has not been changes for quite some time and I am not sure if it is necessary at all.
Create the Excel file
I don't have Excel on my computer so instead of that I am going to use a file created using Excel::Writer::XLSX as explained in the how to create Excel file article.
The script to create the Excel file is here:
#!/usr/bin/perl
use strict;
use warnings;
use Excel::Writer::XLSX;
my $workbook = Excel::Writer::XLSX->new( 'simple.xlsx' );
my $worksheet = $workbook->add_worksheet();
my @data_for_row = (1, 2, 3);
my @table = (
[4, 5],
[6, 7],
);
my @data_for_column = (10, 11, 12);
$worksheet->write( "A1", "Hi Excel!" );
$worksheet->write( "A2", "second row" );
$worksheet->write( "A3", \@data_for_row );
$worksheet->write( 4, 0, \@table );
$worksheet->write( 0, 4, [ \@data_for_column ] );
$workbook->close;
The resulting Excel file looks like this:
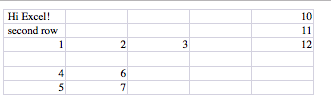
Spreadsheet::Read
Let's see the highest level of abstraction that makes it easiest to access the contents of the Excel file.
Spreadsheet::Read exports a number of function that you either import,
or use with their fully qualified name.
In our solution we are going to import the ReadData function and use the fully qualified name of the other
functions, for no particular reason. Maybe just to show that both work.
The strangely named ReadData function accepts a filename that can be an Excel file, an Open Office Calc file, a Libre Office Calc file,
or even a plain CSV file. It will use the file-extension to guess which format the file is in, it will
load the appropriate back-end module and use that module to load and parse the file. In the end it will create an array reference representing the whole file:
use Spreadsheet::Read qw(ReadData);
my $book = ReadData ('simple.xlsx');
The first element of the returned array contains some general information about the file. Each one of the rest of the elements represent
one of the sheets in the original file. In a CSV file there is only one sheet, but the other formats allow multiple sheets.
So $book->[1] represents the first sheet. It is a hash reference and we can use this to access the content of the cells using
the notation familiar from the spreadsheets. $book->[1]{A1} is the A1 element
say 'A1: ' . $book->[1]{A1};
The output of the above snippet is
A1: Hi Excel!
This can be great if we know exactly which cells to look at, but if we don't know exactly which rows contain data and how many cells have data we need some other tools.
Fetch a row
The row function of Spreadsheet::Read will accept a sheet, and a row-number and will return an array representing the values of
the given row. The size of the returned array depends on the right-most cell that has data. So even though Excel can have many, many columns,
our arrays will only grow to the necessary size.
Cells that are empty will have undef in the respective element of the array.
Because we have not imported the row function, we are using it with its fully qualified name.
The next snippet will read the first row of the first sheet (which is usually represented by the letter A)
and then it will loop over the indexes and display the content of each field. (displaying an empty string if the value was undef).
my @row = Spreadsheet::Read::row($book->[1], 1);
for my $i (0 .. $#row) {
say 'A' . ($i+1) . ' ' . ($row[$i] // '');
}
A1 Hi Excel!
A2
A3
A4
A5 10
Fetch all the rows
Being able to fetch a single row is not enough though. We need to be able to go over all the rows. That's where we can use the
rows function provided by the module. This function too accepts a sheet, but it does not need any more parameters.
It returns an array or array references. Effectively a two dimensional array or "matrix". Each element in the returned array
represents one row in the spreadsheet.
This is how we iterate over all the elements:
my @rows = Spreadsheet::Read::rows($book->[1]);
foreach my $i (1 .. scalar @rows) {
foreach my $j (1 .. scalar @{$rows[$i-1]}) {
say chr(64+$i) . " $j " . ($rows[$i-1][$j-1] // '');
}
}
The result is
A 1 Hi Excel!
A 2
A 3
A 4
A 5 10
B 1 second row
B 2
B 3
B 4
B 5 11
C 1 1
C 2 2
C 3 3
C 4
C 5 12
D 1
D 2
D 3
D 4
D 5
E 1 4
E 2 6
E 3
E 4
E 5
F 1 5
F 2 7
F 3
F 4
F 5
With this we can already work quite well.
Read Excel script
The full script we used to read the excel file:
#!/usr/bin/perl
use strict;
use warnings;
use 5.010;
use Spreadsheet::Read qw(ReadData);
my $book = ReadData('simple.xlsx');
say 'A1: ' . $book->[1]{A1};
my @row = Spreadsheet::Read::row($book->[1], 1);
for my $i (0 .. $#row) {
say 'A' . ($i+1) . ' ' . ($row[$i] // '');
}
my @rows = Spreadsheet::Read::rows($book->[1]);
foreach my $i (1 .. scalar @rows) {
foreach my $j (1 .. scalar @{$rows[$i-1]}) {
say chr(64+$i) . " $j " . ($rows[$i-1][$j-1] // '');
}
}
Comments
How can we read latest version of excel file in perl, i mean 2013 and 2016 versions. Can you suggest any modules?
What sort of Perl version has these Api's or do we individually install them...
you need to install them separately.
i am not able to read from the excel, can you please help me out here? gettting "Parser for XLSX is not installed at"
You need to have the module Spreadsheet::ParseXLSX installed, and in the Perl path for your system
I had a similar problem, solved by doing cpan install Spreadsheet::XLSX
Hi.. Awesome work Gabor. I would really appreciate if you could help me by explaining the snipe from line 17-21. Regrads
The nested loops iterate each column for each row starting with the first row. If you comment out lines 10-15 you will see only the output from lines 17-21.
Hi I am getting this error "Parser for XLSX is not installed at rnew.pl ". Where I am going wrong ,I have just copy-pasted the above same code to check its working.
You need to have the module Spreadsheet::ParseXLSX installed, and in the Perl path for your system. I personally use ParseExcel.
Hi Gabor Szabo, Many thanks for your instructive examples. But, I think that the script "read_excel.pl" works incorrectly when we open the "simple.xlsx" and compare it with the output of the script. It should transpose the indices of column and row instead.
I agree. Gabor created a LITTLE bit of confusion starting with "The next snippet will read the first row of the first sheet (which is usually represented by the letter A)", and proceeded to code accordingly. No biggie -- we just have to be aware of it.
Thanks for this article! But there is a serious error: you have confused rows and columns, and that is causing much confusion among readers.
You wrote: "The next snippet will read the first row of the first sheet (which is usually represented by the letter A)". But spreadsheets do not use letters to represent rows. The COLUMNS are represented as letters, and the rows are represented as NUMBERS. Consequently, the output is incorrectly labeled in the snippet of code that you show for displaying the content of a row. The corrected code should be:
my @row = Spreadsheet::Read::row($book->[1], 1); for my $i (0 .. $#row) { say chr(ord('A')+$i) . '1 ' . ($row[$i] // ''); }
And the output is similarly incorrectly labeled in the snippet of code for fetching all the rows. That corrected code should be:
my @rows = Spreadsheet::Read::rows($book->[1]); foreach my $i (1 .. scalar @rows) { foreach my $j (1 .. scalar @{$rows[$i-1]}) { say chr(ord('A')+$j-1) . " $i " . ($rows[$i-1][$j-1] // ''); } }
Would you be willing to make these corrections in your article?
Below is the input file of excel A B C D APP 1 210101 8.1 APP 2 210102 8.2 APP 3 210103 8.3 Data 4 210104 8.4 Data 5 210105 8.5 Data 6 210106 8.6
How to generate seperate output files of excel for APP and Data
